Introduction
This is the final project of INFSCI 2140 Information Storage and Retrieval. We built a search engine of movie lines. Users can input a phrase or a complete sentence and it returns a list of best matched movies with excerpts.
Teammates
- Zijian Xu
- Long Yan
Data Source
https://nlds.soe.ucsc.edu/fc2 Film Corpus 2.0
It contains 960 film scripts including dialogues and scene descriptions.
Tools
- Backend: Spring MVC
- Frontend: Angular 7
- Cloud & Deployment: Microsoft Azure Cloud
- Library: Apache Lucene
Implementation
Data Processing
- Remove space lines and special characters
- Tokenize and normalize the terms with Porter Stemming
Data Pipeline
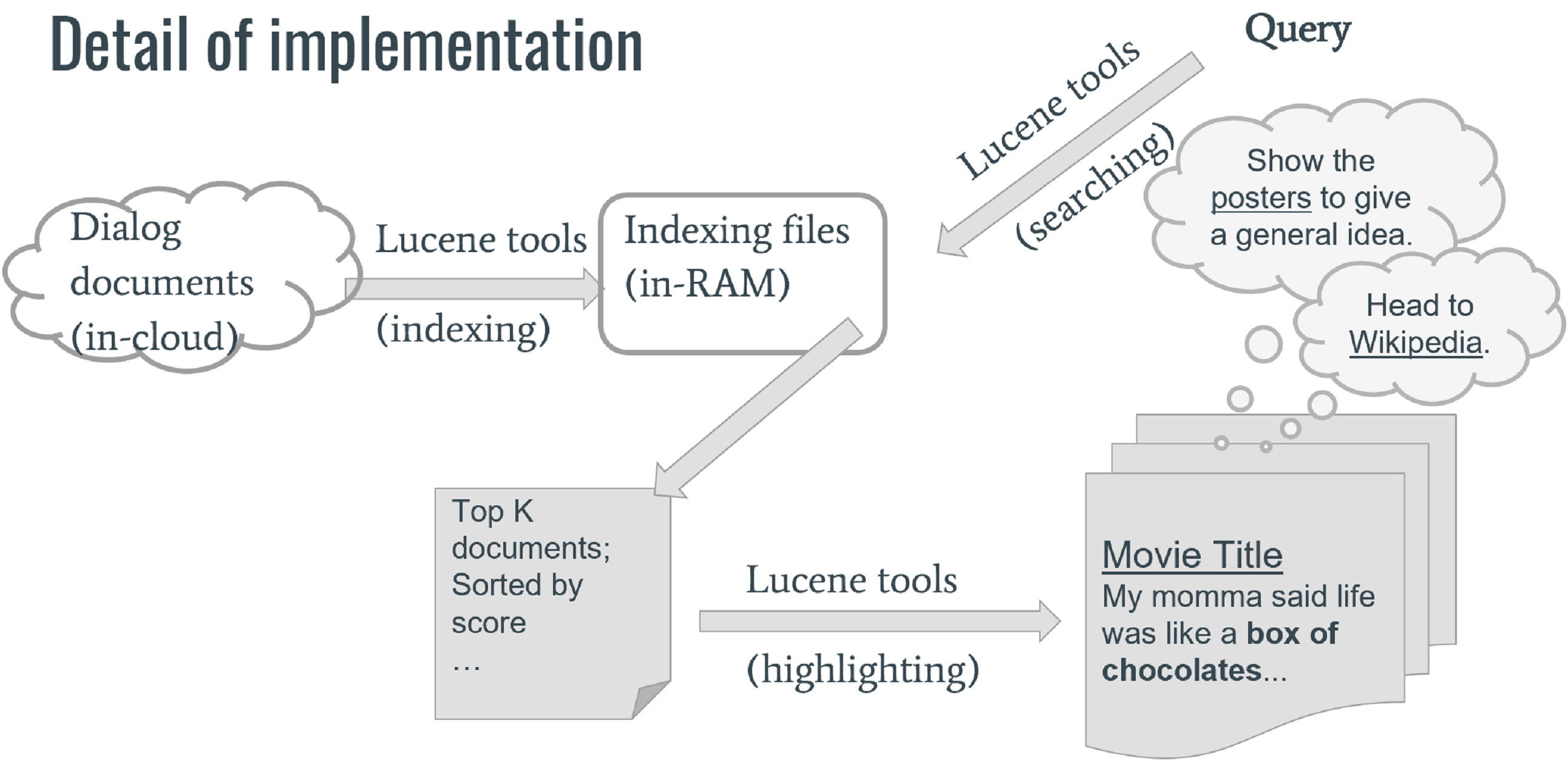
Indexing – Index Writer
- Fetch movie script documents from cloud
- Write index files with Lucene into RAM
- Run once with starting the server
Searching – Index Reader
- Tokenize query words
- Search for the documents with Lucene
- Get surrogate fragments with Lucene highlighter
Use Case
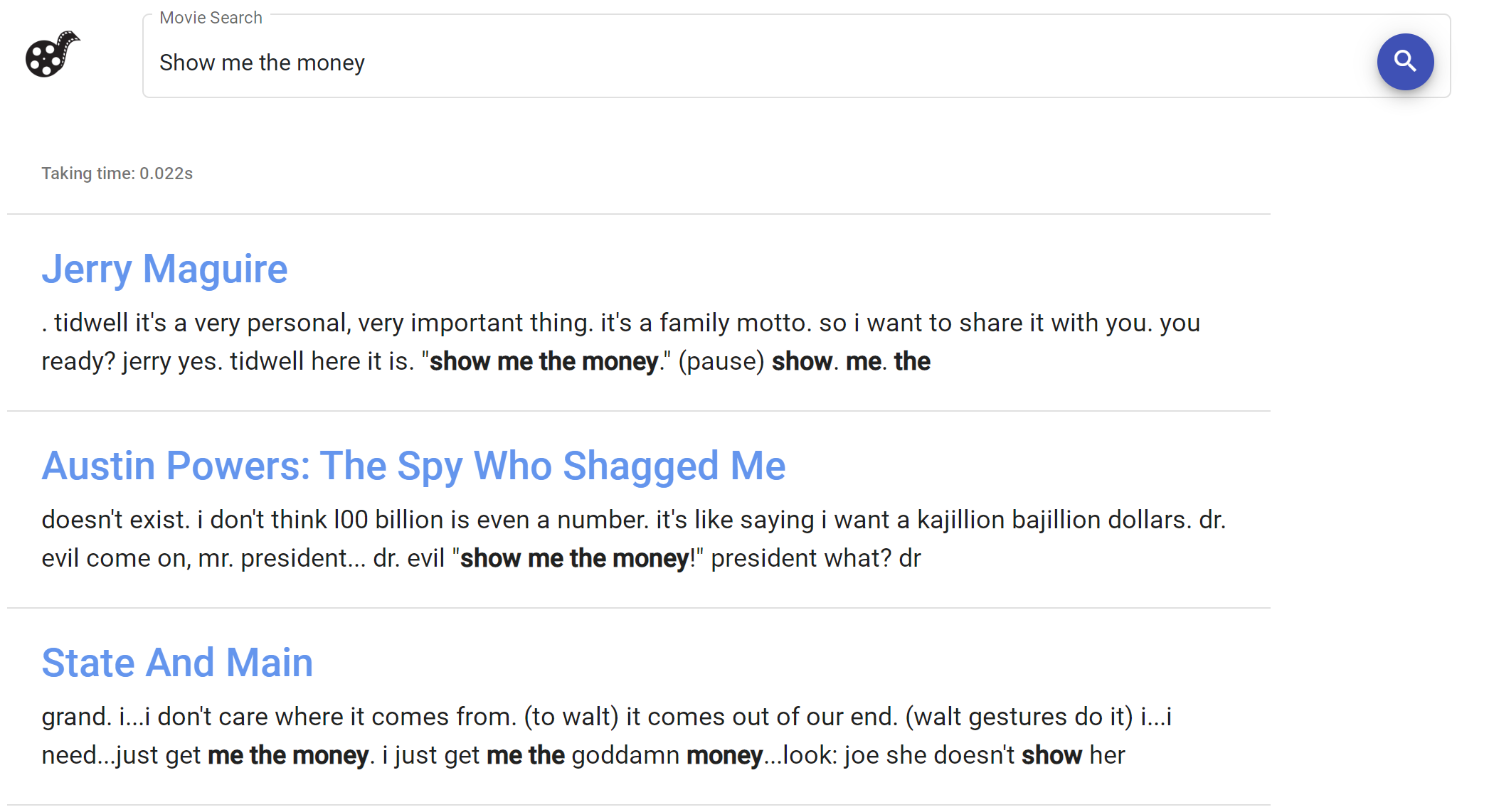
Users input a phrase or sentence like “show me the money”, and our system outputs:
References
Film Corpus
Walker, Marilyn A., Ricky Grant, Jennifer Sawyer, Grace I. Lin, Noah Wardrip-Fruin, and Michael Buell. “Perceived or Not Perceived: Film Character Models for Expressive NLG.” BEST PAPER AWARD. In International Conference on Interactive Digital Storytelling (ICIDS), Vancouver, Canada, 2011.
Marilyn A. Walker, Grace I. Lin, Jennifer E. Sawyer. “An Annotated Corpus of Film Dialogue for Learning and Characterizing Character Style.” In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC), Istanbul, Turkey, 2012.